Framework for scaling analytics – Data 2030 summit



A typical data architecture diagram shows ingesting raw data passing through levels of curation & transformation, building a data model and finally generating analytics. This structure is pretty standard in most diagrams and seems to be a very straight forward way of designing an analytics solution. The stages tools and platforms might vary depending on various factors but the basic building blocks usually stays the same.
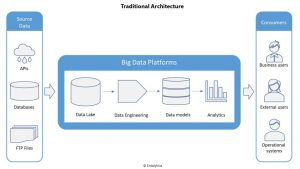
These solutions are driven by common requests data engineers get – which are focused around business rules to cover, data load requirements, latency & performance. What we often miss out factoring is ‘rapid change’. Software solutions are expected to change which understood, however the kind of change analytics solutions have to go through is a bit different in nature.
Analytics solutions combine data from various sources and generate insights. As we add more sources, explore more data, learn more from the data we have and look for more insights our data models & analytics change. This is a perfectly normal cycle through which any data solution is expected to go through. The tricky part is: these changes are to be expected to be A LOT and VERY frequent. Therefore the need for ‘rapid change’ becomes more important and challenging.
The common architecture flow we talked about, while seems nice & tidy – it also tightly couples different stages together which makes updates time consuming and deployment harder. Even if a change might be as simple much as adding a new SQL statement, with this structure the change process would need a proper solution design, implementation complexities, rigorous tests and deployment pains.
Over time these ‘inefficiencies’ in deploying changes & solutions starts to put engineers at odds with the stakeholders and leads to further complications. If you’ve been working on data analytics projects for some time, this story is not new to you at all.
I still sometimes get confused on the definition of DataOps, and there are quite a few out there. The way I understand DataOps is as follows:
Before going more into DataOps, I want to discuss the problem we want to solve – painful updates. While all the 4 aspects mentioned above contribute to make updates less painful, SOA architecture and data quality checks have a larger contribution.
A while ago when building big monolith backend systems was the norm, SOA architecture came in and we started to see microservices popping up everywhere. Now we know changing a microservice is far more easier than making changes to a monolith. The same goes with data pipelines.
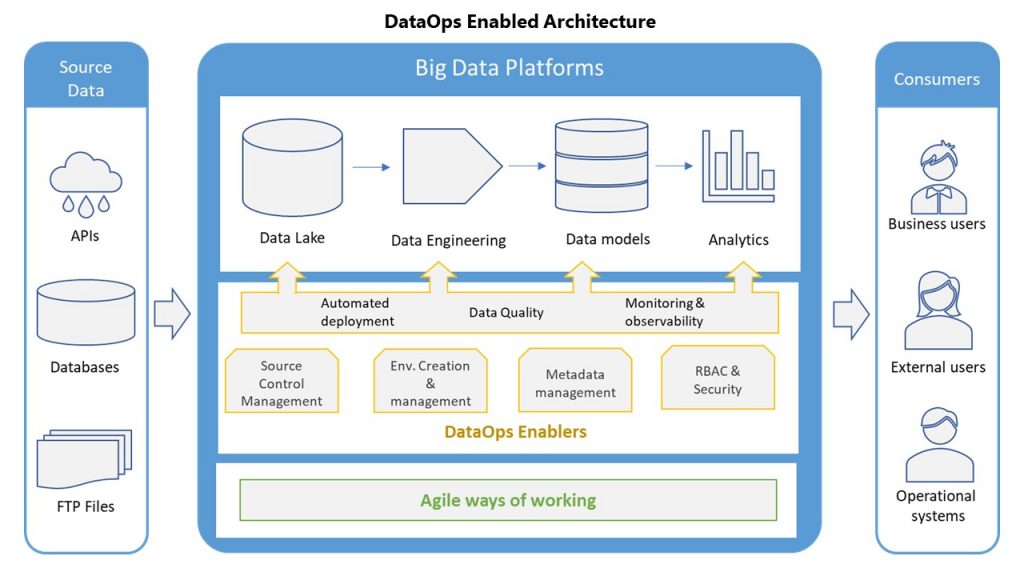
Traditionally data engineers have big blocks of workflows – ingestion & data lake, data engineering & data models, analytics / visualizations. Within these three blocks is a giant web of workflows which are very dependent on one another. If one fails, you see cascading failures and it’s takes some digging to figure out what failed where. Also connectivity between these blocks is sometimes blurred, there aren’t very clear ‘contracts’ of what is to be expected as an output from each stage making them all very tightly coupled.
All components (individual ETLs) across these blocks should be self-contained with clear contracts of what they receive and what they serve as a result. Same goes across different stages in the overall pipeline. Self-contained & reusable workflow components make it easier to develop code isolated changes to individual components and deploy them. Also it allows for trying out / swap around different tools / platforms across the pipeline since all each component should care about is servicing the contract.
Coming back to DataOps, here are a few prominent components of a DataOps architecture.
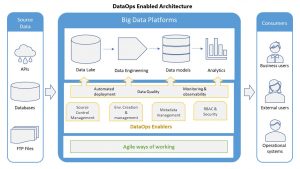
Having a code branching / merging strategy used for all product code and infrastructure as code is crucial. While every team is using some kind of source control management tool, sometimes the lacking is in the branching / merging strategy. Keep repos modularized and avoid having long lived feature branches.
Ability to spin up and tear down compute & storage resources as required. For ease of maintainability & reusability, have infrastructure as code. If possible using SaaS services can make this even easier, with a tradeoff of additional cost
Using Continuous Integration tools ability to deploy code & workflows across different environments (dev, staging, production). CI tools usually also configure different quality gates across CI pipelines to validate the code quality & perform regression tests.
Have automated tests to regress the data pipeline’s functionality validating any new updates are not breaking old functionality and everything is working the way it is intended.
Manage different types of metadata to allow for having all users a common understanding of the data assets and ease of updating.
Have access controls on all the data assets to secure the data & be compliant with regulatory requirements. Role based access controls (RBAC) are one kind of control mechanism, you’d want to have encryption and other security measures to ensure the safety of your data as well.
Simply put – have real time insight into the health of your data in production across the data pipelines. In case of any data anomalies have automated self-healing steps for simpler problems (e.g. workflow did not execute completely) or alerts for complicated issues (data from two source mismatching).
We talked about rapid change, team predictability gives a trend of how ‘predictable’ are the deliverables from a team. Measuring this can be a little tricky, but if your work tracking tool (e.g. JIRA) is configured correctly, it’s certainly doable.
How much work a team can churn out. As the practices discussed above mature, over time the team’s velocity should increase. This is accomplished by – getting smarter in prioritizing work that really matters and ability to release more features in less time.
The ability to make rapid changes to your data pipeline, and democratize the ability to change as much as possible is no longer optional or good to have – It’s a must. The speed at which markets change, new sources come in, new problems statements come in to get solved keep on increasing. Therefore the need to quickly churn out new solutions & update existing ones is all too common and can be cited as one of the biggest challenges data programs face today.
While the word DataOps might seem fancy, the concepts being discussed under it are mostly not novel ideas and have been part of the evolution of design practices. In my humle opinion DataOps just helps with the confusion of how to apply these principles in data analytics projects.
If after reading all this your wondering – that’s a lot of work and not sure if this will pay off, teams without these practices end up spending way more effort anyway and the output is still slow and low quality. Might as well take a chance and make a few changes & see how it goes!

Getting familiar with the basics of data analytics can be a daunting task. With so many buzz words flying around and different technologies involved often folks get confused and takes time get the basics right.
This workshop was designed to demystify starting with data analytics & data quality for:
Before we talk about data quality, it was important to give an into to big data, data pipelines and all the stages across the pipeline.
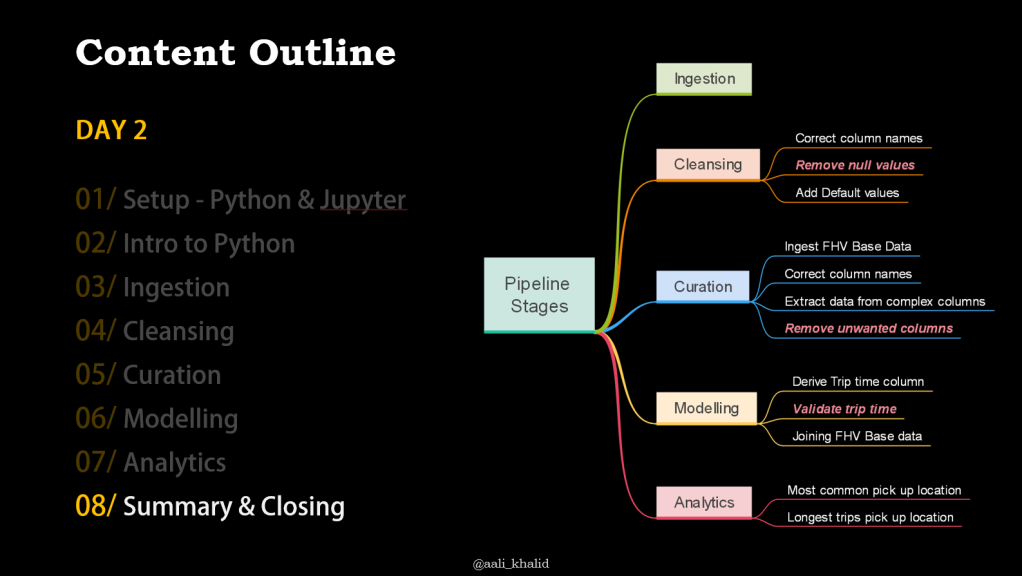
Across the 2 hour sessions on two days, we first discussed the:
The first day was mostly to get the basics & internalize the activities at each stage without going more technical into the code

Once folks had an idea of what needs to happen at each stage, on the second day participants went about practically implementing all stages in the pipeline.
This was tricky when I was planning the workshop. With most workshops, after some basic theory participants jump onto coding. I’ve always found that to be a rough transition which makes it hard for participants to follow along with, especially if they are working not writing code on a daily basis.
Therefore, the first day was to understand the concepts, the secret was not just death by PowerPoint – but participants actually performing the steps across the pipeline / but not with code. To make life easy, we did that with excel – no tooling knowledge required – pure focus on understanding the WHY of each activity!
The second day was all about coding with baby steps. We started from:
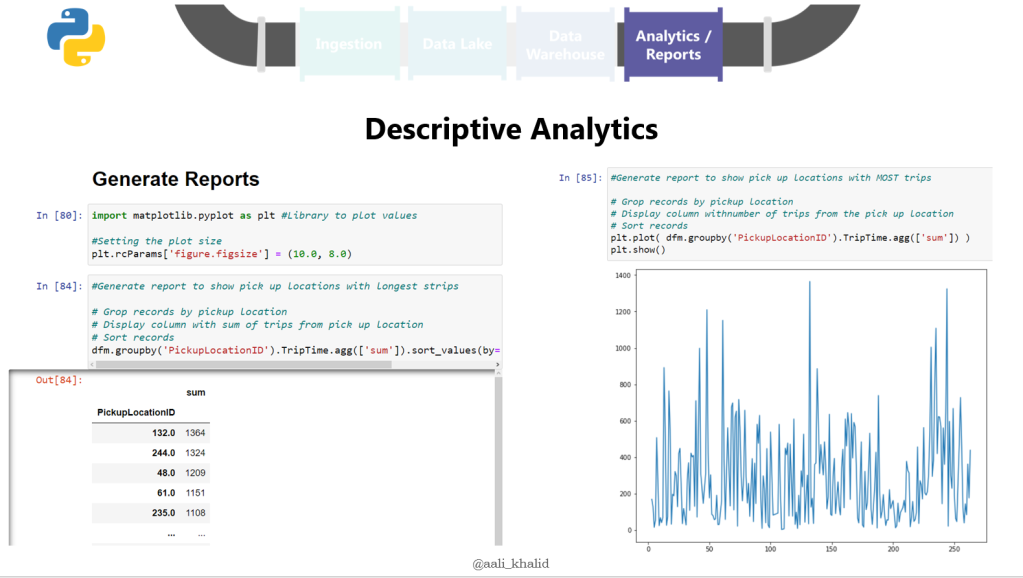
The code was quite a bit to go over, but was designed in such a way that participants can easily follow along afterwards by providing ample documentation within the code.
The content we covered was A LOT, I think could have easily been done in 6 hours instead of 4. It was a toss between dropping content and trying to cover more in less time.
That’s where my personality kicks in – I have a hard time cutting down on content – because I feel I need to share what I know, I’ve experienced the struggle of learning this – and hope people who learn from me don’t have to struggle as much.
“Explaining things in a very simple manner, Engaging answering questions patiently – Content is Solid and awesome presentation”
Participant feedback


Organizations when start on their data analytics journey, it mostly begins as an MVP (Minimum Viable Product) and evolved over time. While that is exactly how things should go – sometimes they miss out on building the foundations right as they evolve their MVP. A big factor that get’s missed is around data quality, data governance & stewardship.
From my experience building a data pipeline it not the challenging part – ensuring data saved in our warehouse is of quality (fit for purpose) is the tricky part. Unfortunately this is easier said than done and requires some foundational work and structure to consistently deliver quality data.
In this talk at TestBash New Zealand 2020 I gave a quick introduction to how data analytics works and discussed some basics of building quality into your data pipeline.
It’s surprising how easy it is for teams to forget the importance of having ‘fit for purpose’ data – be that for business intelligence, analytics and especially AI / ML initiatives. This is precisely what I like to remind teams I work with is – it all starts with having the right data.
For building enterprise data assets, often we get data from a lot of different sources across the organization & perhaps from 3rd part sources also. These sources have their own paradigms in which the data is developed and consumed, and may not always be consistent with one another.
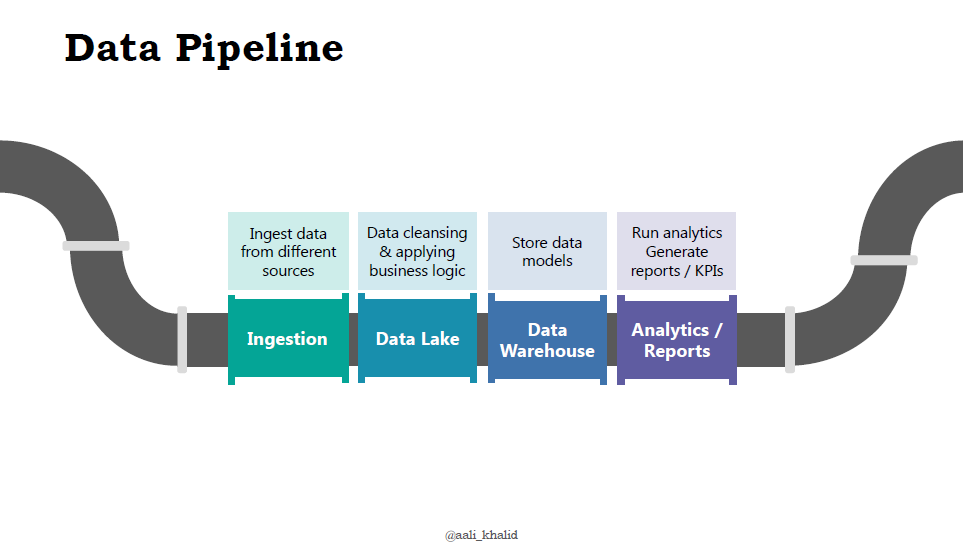
To homogenize all this data and make it fit for purpose, it passes through a lot of different stages of cleansing, curating, transforming and modelling. All these activities combined are called the data pipeline.
Image below gives a high level overview of a sample data pipeline:
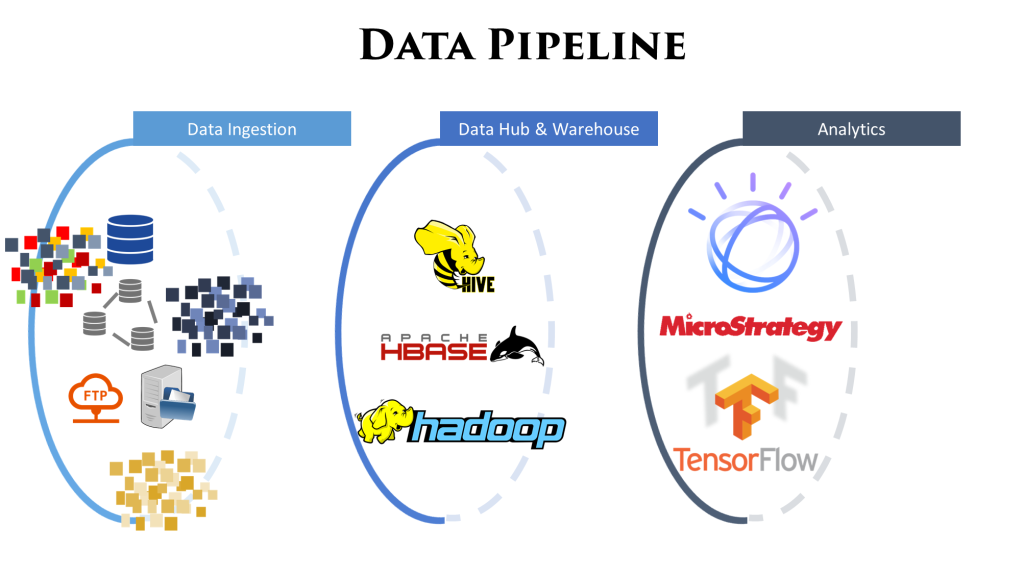
To get the desired output from analytics, the quality of data across the data pipeline has to be measured and fixed. It happens at the analytics stage we get data which might not add up. Backtracking from there to figure out exactly what went wrong is a tedious job.
To avoid this, data quality must be measured across all stages. Here is a sample process to writing these quality checks:

At different stages, different type of data quality checks might be more important. While ingesting data we would be more concerned if the source data is as per the defined schema. As we move along the pipeline the objectives of the checks change according to the underlying ETL process.
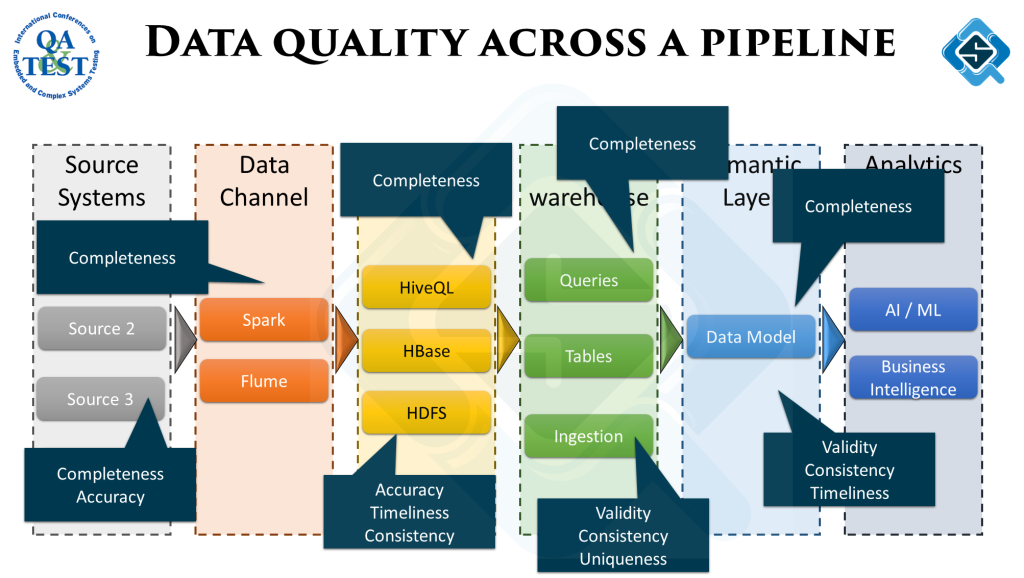
Getting quality of the data right is always a journey and never ends. Being agile about this and consistently working on feedback gathered from these quality checks is paramount for success in any data analytics initiative.