Data Quality in Real time
When I started working in Data & analytics projects, I realized testing a workflow during development is only ‘part’ of the story. We can ‘assume’ what kind of data we will get in production, but cannot be certain, therefore testing data quality in real time is going to be paramount.
On reading, exploring & supporting to fix data quality issues, the importance of these checks became evident. Over the years I’ve seen exponential impact of these checks and now are always a integral part of any data strategy I work on. The impact these checks have had are tremendous, I’ll highlight a few of the important ones here.
Builds trust in analytics
This is usually the toughest part of any data program – to build trust with decision makers in the analytics results being presented. A common obstacle to building that trust is skewed information coming out of the analytics – caused by data quality issues across he data pipeline.
When the analytics team is questioned about it – naturally it takes them time to figure out what could be the problem. With complex data pipelines the challenge is compounded and often can take a while to figure out the source of the problem. This slowness creates further distrust and takes away team’s capacity from delivering new features and instead spent on debugging old ones.
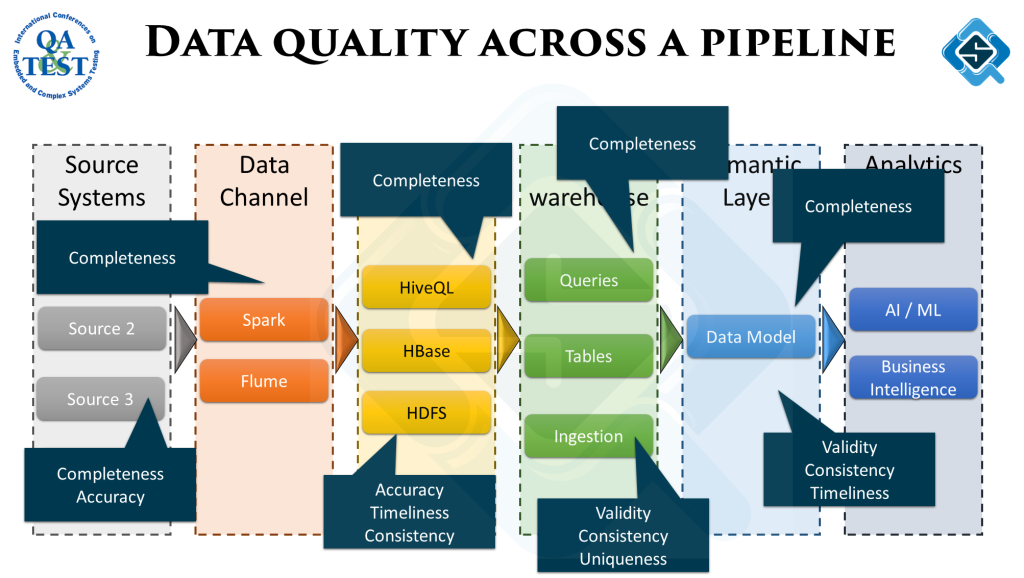
Once teams start to run data quality checks across different stages in the data pipeline, they are capable to identify data quality issues almost as soon as they occur. Teams are then able to preemptively highlight a potential data quality issue and very well equipped to fix the problem as well, since source of the problem is very easy to find now.
This changes the conversation from “why the data isn’t making sense” to proactive alerting of a potential upcoming data quality issue which might cause skewed metrics – and sometimes fixing the problem even before consumers get a chance to look at the alerts or skewed results.
Reduced rework
Analytics teams spending time on debugging data quality issues is a common activity you’d find on their sprint boards (unfortunately). True, there will always be ‘some’ capacity going towards this – simply because usually teams have very less control on the data ingested into the data lake. However this can get very bad if appropriate enablers are not in place, I’ve seen the amount of rework going as high as 50% of team’s capacity across a PI (quarter)!
With data quality checks running in production across the pipeline – this manual toil significantly reduces and teams mostly don’t have to spend time ‘finding’ the cause of the problem, instead have a very good idea of the problem source.
Mental peace
Not to mention the mental peace teams get from this. The thought of you never know what kind of nasty data might make it’s way into your analytics is pretty draining. Once teams see the this benefit – they often become the biggest drivers of implementing these checks.
Patterns of issues
Ever felt Deja vu while fixing an issue? Yeah that’s all too common. Over a longer period of time the similar kind of issues might keep coming up again and again. Since the occurrences are spread across time – not easy to make the connection.
With running data quality checks in real time – teams build a very valuable data set showing data quality across the pipeline over a longer period of time. Capturing trends and correlating them with possible causes becomes easier.
How to build Data quality checks?
There are a couple of ways I’ve seen this built – in a separate post will talk about how some best practices in building these checks.