Organizations when start on their data analytics journey, it mostly begins as an MVP (Minimum Viable Product) and evolved over time. While that is exactly how things should go – sometimes they miss out on building the foundations right as they evolve their MVP. A big factor that get’s missed is around data quality, data governance & stewardship.
From my experience building a data pipeline it not the challenging part – ensuring data saved in our warehouse is of quality (fit for purpose) is the tricky part. Unfortunately this is easier said than done and requires some foundational work and structure to consistently deliver quality data.
About the talk
In this talk at TestBash New Zealand 2020 I gave a quick introduction to how data analytics works and discussed some basics of building quality into your data pipeline.
It all starts with data
It’s surprising how easy it is for teams to forget the importance of having ‘fit for purpose’ data – be that for business intelligence, analytics and especially AI / ML initiatives. This is precisely what I like to remind teams I work with is – it all starts with having the right data.
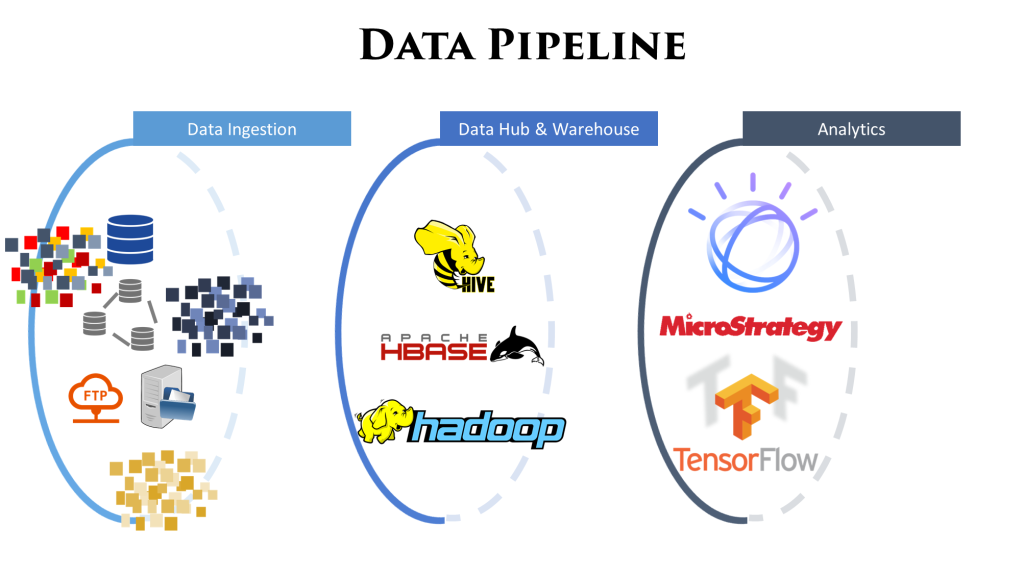
The Pipeline
For building enterprise data assets, often we get data from a lot of different sources across the organization & perhaps from 3rd part sources also. These sources have their own paradigms in which the data is developed and consumed, and may not always be consistent with one another.
To homogenize all this data and make it fit for purpose, it passes through a lot of different stages of cleansing, curating, transforming and modelling. All these activities combined are called the data pipeline.
Image below gives a high level overview of a sample data pipeline:
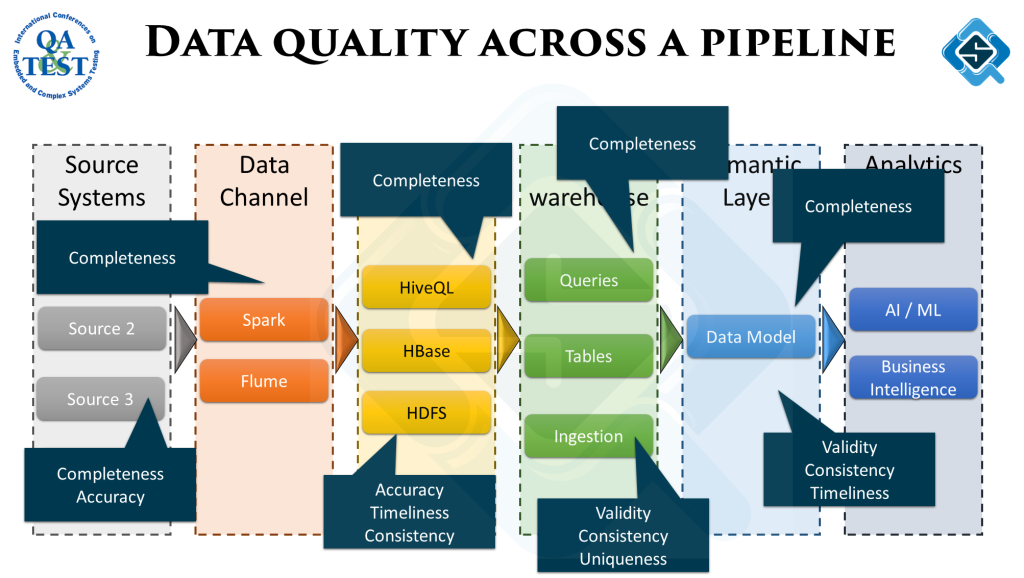
Data Quality
To get the desired output from analytics, the quality of data across the data pipeline has to be measured and fixed. It happens at the analytics stage we get data which might not add up. Backtracking from there to figure out exactly what went wrong is a tedious job.
To avoid this, data quality must be measured across all stages. Here is a sample process to writing these quality checks:

At different stages, different type of data quality checks might be more important. While ingesting data we would be more concerned if the source data is as per the defined schema. As we move along the pipeline the objectives of the checks change according to the underlying ETL process.
Getting quality of the data right is always a journey and never ends. Being agile about this and consistently working on feedback gathered from these quality checks is paramount for success in any data analytics initiative.
