Snowflake Tips
Snowflake is a powerful tool, which makes creating data models very easy and convenient – with the speed of distributed computing on the cloud. A common mistake engineers do is using the tool as they ‘think’ it should work instead of how the tool was ‘intended to be used.
Role based access control
Snowflake makes managing user access easy and slick – an individual if assigned multiple roles can switch between them fairly easily. Also resources created with one role cannot be accessed by another – unless it’s a higher role which through RBAC inheritance can access those resources.
Pre-defined roles
TIP – It helps to remember the five pre-defined RBAC roles and how they are related.
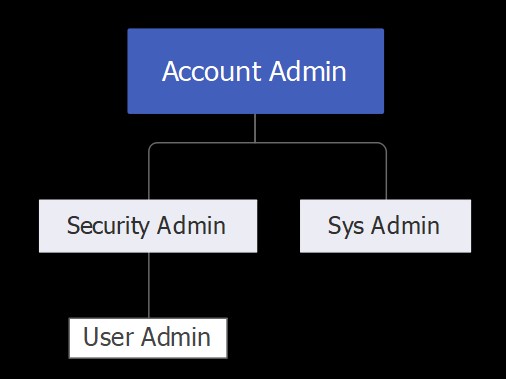
Using the right role
While creating data assets or components to be used within those assets, you will be able to access them only if working with that role – or a higher role with custodian oversight.
TIP – Ensure while creating or using data assets you are working with the right role
Ingesting files
During initial exploration of your data asset, you most probably will have to ingest semi-structured data to do some data profiling or analysis. While the wizard for loading data in tables is quite easy, I prefer to use code wherever possible.
Creating File Format
-- Create file format to ingest semi-structured data
-- Remember to execute using the right user role!
CREATE FILE FORMAT dbNAme.schemaName.tableName
TYPE = 'JSON'
COMPRESSION = 'AUTO'
ENABLE_OCTAL = FALSE
ALLOW_DUPLICATE = FALSE
STRIP_OUTER_ARRAY = TRUE
STRIP_NULL_VALUES = FALSE
IGNORE_UTF8_ERRORS = FALSE;
Working with JSON files
It’s often a good practice to ingest raw data as it is, and then cleanse and curate in subsequent steps of your pipeline. But looking at raw data in one column can be tricky – a neat way to visualize it:
SELECT
column_name:"key_name"::<datatpe> AS col_name_to_display,
col_1:"key_1"::STRING AS first_column,
col_1:"key_2"::STRING AS second_column
FROM table_name;
To flatten semi-structured data is quite easy as well, helps in visualizing what the data may look like before going ahead and creating all those tables.
SELECT
value:key_1::VARCHAR AS First_Column,
value:key_2::VARCHAR AS Second_Column
FROM table_name,
LATERAL FLATTEN(input => column_name:root_key);
You might want to cast a value from some key/value pairs as well and display them nicely in the results:
SELECT
column_name:key_name:nested_key_name AS col_display,
column_name:key_name AS col_display,
value:nested_key_name::VARCHAR AS HASHTAG_TEXT --casting to varchar
FROM table_name,
LATERAL FLATTEN
(input => column_name:key_name:nested_key_name);
After all this is done – you’d want to create a view from this for users to be able to read raw data
create or replace view database_name.schema_name.table_name as(
SELECT
column_name:key_name:nested_key_name AS col_display,
column_name:key_name AS col_display,
value:nested_key_name::VARCHAR AS HASHTAG_TEXT --casting to varchar
FROM table_name,
LATERAL FLATTEN
(input => column_name:key_name:nested_key_name);
);
