Among all the online conferences, Automation Guild is the best automation conference I happily attend, this year was a pleasure to speak at it again. If you are in automation, I think this is a must attend conference. In this post I’ll give a brief overview of my talk at the conference.
The subject of big data is exciting, but I’ve felt there is a general lack of testing maturity in the space. I guess since the industry itself is comparatively new and is evolving. The walk was to share some basics about big data and how testing & automation works in this field.
About big data
The evolution into big data has been fueled by technologies which have made processing lots of data at high speeds easy, and most importantly the ability to react to the insights very quickly. We discussed all these factors quickly, summarized in this image:

What are big data projects all about
The objective of big data projects is to gather insights / analytics to understand and solve problems. For that to happen, data from few or many sources may be needed to run analytics on. Now acquiring the data is usually not a big problem, to get it into a structure where it all makes sense collectively – is the challenge.
That’s where the concept of a data pipeline comes in. The data is passed through different stages of ‘transformation’ / ETL (Extract, transform, load) to make it more usable for our problem at hand.
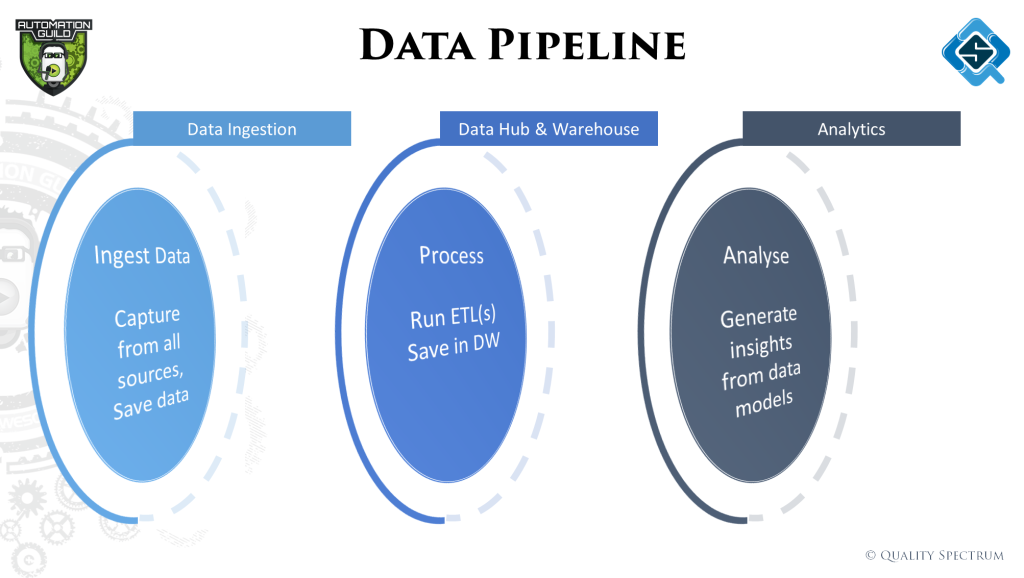
Testing in Big data
Like Web applications have some standard tests that happen, similarly in big data there are some tests which are common. However, they are nothing like the ones we do for web applications.
In data projects, all we are dealing with is ‘data’, data in and data out. The challenge is transforming the data as expected and building models which actually solve our problems. Therefore, most testing in this industry revolves around ‘Data Quality’.

Within the three stages of the data pipeline, there can be many ETL activities happening within. For each ETL, deciding what type of data quality checks are needed is important. In the talk we walked through a basic process of how to determine that.
Automating tests
Because of the kind of tests we have in the big data space, automation also works quite differently. It’s more about fetching sets of data and checking if the right logic / business rules was applied. To perform these activities, some data platforms provide the capability of doing that easily, if not the technologies used to build these ETL flows are also then used to test them.
Talking about languages, Python is used widely because of it’s data processing capability. These scripts are used within workflows to do the required validations. The most common validation is checking of all data has been copied from point A to B. Sometimes while moving data from one space to another, files or records get missed, maybe they get truncated or other reasons. This is just one of the 6 quality dimensions.
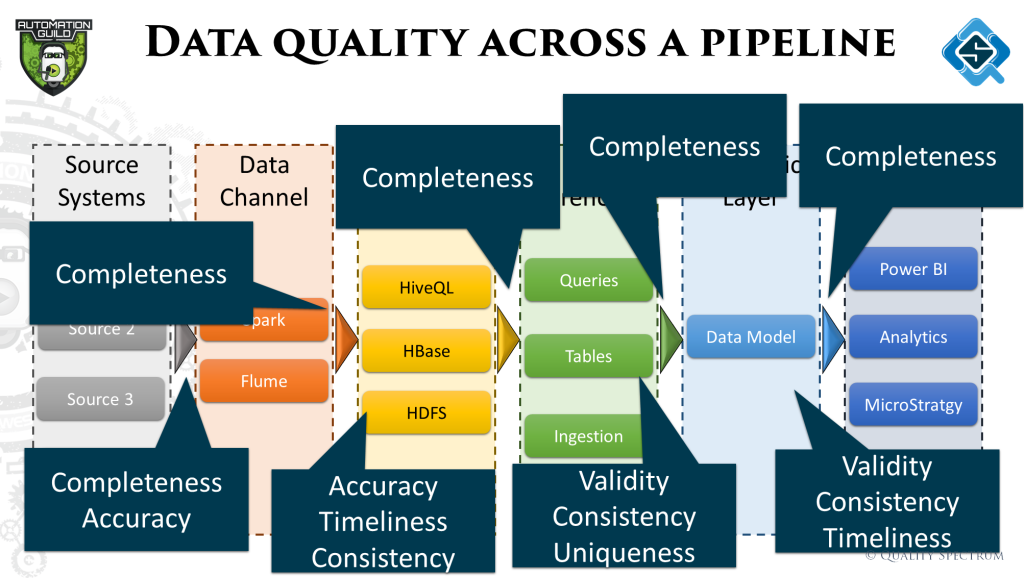
Data quality across the pipeline
In the talk we walked through a sample pipeline and explained the kind of tests that can be done and how these tests would be executed. The image below summarizes all the checks discussed. The data pipeline was also expanded to show activities happening within the three stages and how they are teste

1 thought on “Big data 101 and Importance of Automation”
Thanks for your blog, nice to read. Do not stop.