The subject of Big data fascinates people and businesses. While this might be just a buzz word, big data is immensely helpful to unearth important information and in the 21st century, information is power.
In this post, I’ll summarize my talk at the OnlineTestConf2019 titled “Why we call it big data and how to test it”. The talk was also recorded and can be watched on YouTube here.
An intro to big data
I start with talking about little bit history of Big data and what factors fueled growth and innovation in this industry.
Next we put ‘Big’ into perspective to help in understand the sheer size of data and the challenge it poses to process it.

Defining Big data
When would a project classify as big data? Is it only the size of data? This slide explains the different ways we tried to classify it and the most common method used.

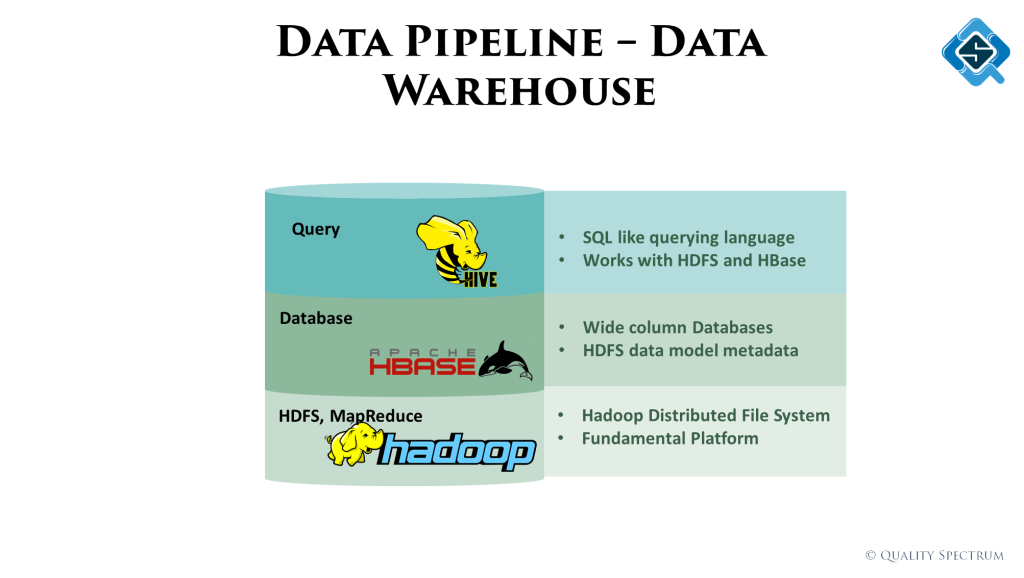
The Hadoop platform
Hadoop is the most widely used big data platform which is also open source. I talk about it’s widely used MapReduce process and different products within like HDFS, HBase and HiveQL.
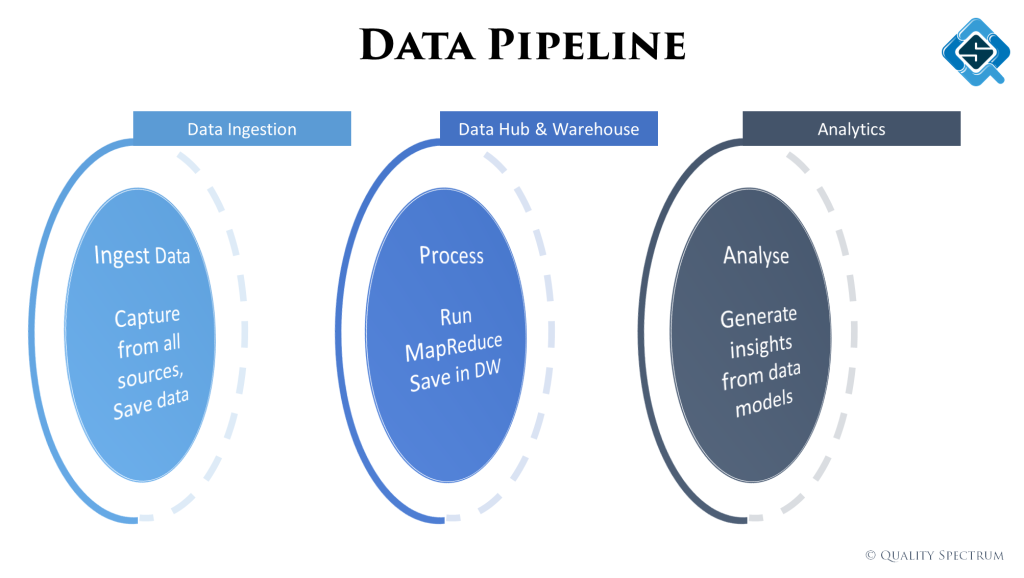
The Data Pipeline
All we are doing in a big data project is collect data from different sources, hash it up into meaningful big tables and generate insights from it. There are three main phases you might have in a big data project.
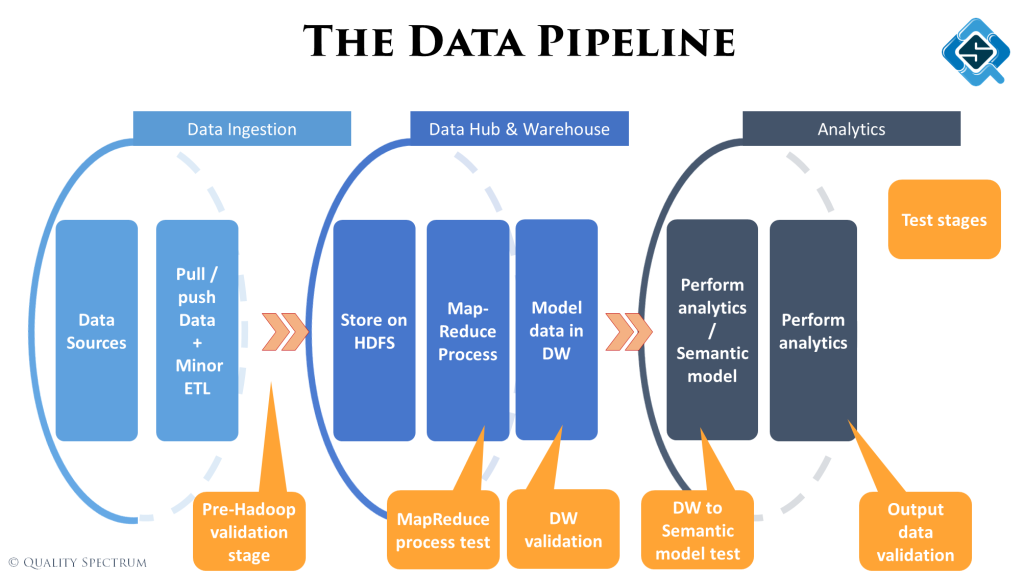
Testing stages
At the end we quickly skim through the different type of tests we perform across the pipeline. At each stage, depending on the type of activities being performed, the type of tests will be different.
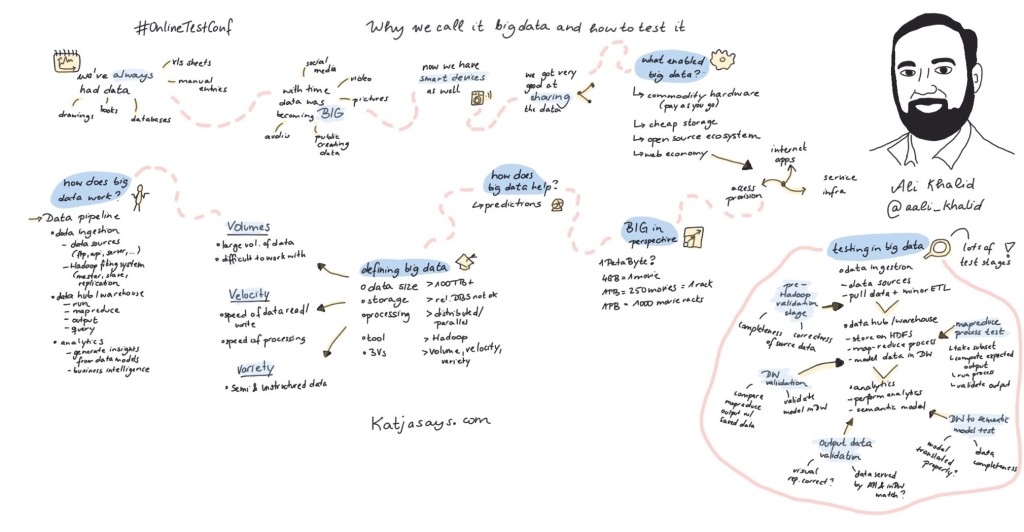
Summary
Katjya did a very good sketch summarizing the talk she mentioned in her tweet.