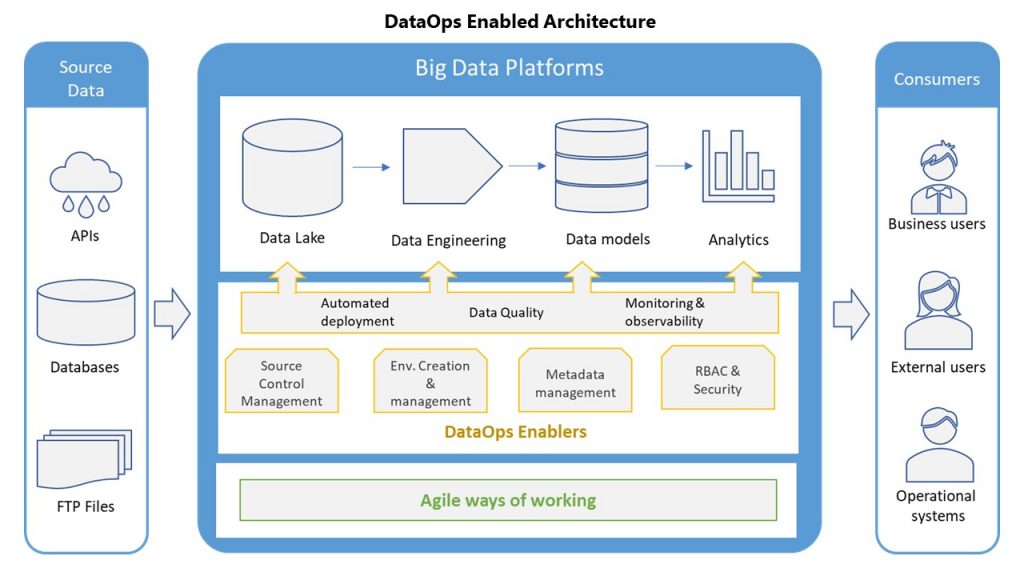
Typical data architecture
A typical data architecture diagram shows ingesting raw data passing through levels of curation & transformation, building a data model and finally generating analytics. This structure is pretty standard in most diagrams and seems to be a very straight forward way of designing an analytics solution. The stages tools and platforms might vary depending on various factors but the basic building blocks usually stays the same.
The requirements we consider
These solutions are driven by common requests data engineers get – which are focused around business rules to cover, data load requirements, latency & performance. What we often miss out factoring is ‘rapid change’. Software solutions are expected to change which understood, however the kind of change analytics solutions have to go through is a bit different in nature.
Rapid change is inevitable
Analytics solutions combine data from various sources and generate insights. As we add more sources, explore more data, learn more from the data we have and look for more insights our data models & analytics change. This is a perfectly normal cycle through which any data solution is expected to go through. The tricky part is: these changes are to be expected to be A LOT and VERY frequent. Therefore the need for ‘rapid change’ becomes more important and challenging.
Painful to update
The common architecture flow we talked about, while seems nice & tidy – it also tightly couples different stages together which makes updates time consuming and deployment harder. Even if a change might be as simple much as adding a new SQL statement, with this structure the change process would need a proper solution design, implementation complexities, rigorous tests and deployment pains.
Putting teams at odds
Over time these ‘inefficiencies’ in deploying changes & solutions starts to put engineers at odds with the stakeholders and leads to further complications. If you’ve been working on data analytics projects for some time, this story is not new to you at all.
DataOps to the rescue
I still sometimes get confused on the definition of DataOps, and there are quite a few out there. The way I understand DataOps is as follows:
- Following Agile practices to push results iteratively
- Incorporate DevOps culture & practices of CI/CD pipelines and creating environments on the fly
- Measuring data quality across the pipeline
- Modularized / SOA architecture
Solving painful updates
Before going more into DataOps, I want to discuss the problem we want to solve – painful updates. While all the 4 aspects mentioned above contribute to make updates less painful, SOA architecture and data quality checks have a larger contribution.
SOA – microservices & pipelines
A while ago when building big monolith backend systems was the norm, SOA architecture came in and we started to see microservices popping up everywhere. Now we know changing a microservice is far more easier than making changes to a monolith. The same goes with data pipelines.
Traditionally data engineers have big blocks of workflows – ingestion & data lake, data engineering & data models, analytics / visualizations. Within these three blocks is a giant web of workflows which are very dependent on one another. If one fails, you see cascading failures and it’s takes some digging to figure out what failed where. Also connectivity between these blocks is sometimes blurred, there aren’t very clear ‘contracts’ of what is to be expected as an output from each stage making them all very tightly coupled.
Modularize your pipelines
All components (individual ETLs) across these blocks should be self-contained with clear contracts of what they receive and what they serve as a result. Same goes across different stages in the overall pipeline. Self-contained & reusable workflow components make it easier to develop code isolated changes to individual components and deploy them. Also it allows for trying out / swap around different tools / platforms across the pipeline since all each component should care about is servicing the contract.
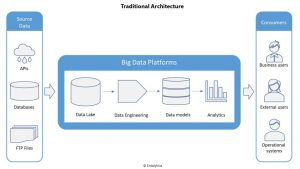
DataOps
Coming back to DataOps, here are a few prominent components of a DataOps architecture.
DevOps
Branching/Merging
Having a code branching / merging strategy used for all product code and infrastructure as code is crucial. While every team is using some kind of source control management tool, sometimes the lacking is in the branching / merging strategy. Keep repos modularized and avoid having long lived feature branches.
Environment orchestration & management
Ability to spin up and tear down compute & storage resources as required. For ease of maintainability & reusability, have infrastructure as code. If possible using SaaS services can make this even easier, with a tradeoff of additional cost
Automated deployment
Using Continuous Integration tools ability to deploy code & workflows across different environments (dev, staging, production). CI tools usually also configure different quality gates across CI pipelines to validate the code quality & perform regression tests.
Automated tests
Have automated tests to regress the data pipeline’s functionality validating any new updates are not breaking old functionality and everything is working the way it is intended.
Data Governance
Metadata management
Manage different types of metadata to allow for having all users a common understanding of the data assets and ease of updating.
- Business metadata – business owners & business rules
- Technical metadata – database structures & allowed values
- Operational metadata – Data lineage & data currency
Security and Access controls
Have access controls on all the data assets to secure the data & be compliant with regulatory requirements. Role based access controls (RBAC) are one kind of control mechanism, you’d want to have encryption and other security measures to ensure the safety of your data as well.
Data quality in production
Simply put – have real time insight into the health of your data in production across the data pipelines. In case of any data anomalies have automated self-healing steps for simpler problems (e.g. workflow did not execute completely) or alerts for complicated issues (data from two source mismatching).
Agile ways of working
Team predictability
We talked about rapid change, team predictability gives a trend of how ‘predictable’ are the deliverables from a team. Measuring this can be a little tricky, but if your work tracking tool (e.g. JIRA) is configured correctly, it’s certainly doable.
Team velocity
How much work a team can churn out. As the practices discussed above mature, over time the team’s velocity should increase. This is accomplished by – getting smarter in prioritizing work that really matters and ability to release more features in less time.
Conclusion
The ability to make rapid changes to your data pipeline, and democratize the ability to change as much as possible is no longer optional or good to have – It’s a must. The speed at which markets change, new sources come in, new problems statements come in to get solved keep on increasing. Therefore the need to quickly churn out new solutions & update existing ones is all too common and can be cited as one of the biggest challenges data programs face today.
While the word DataOps might seem fancy, the concepts being discussed under it are mostly not novel ideas and have been part of the evolution of design practices. In my humle opinion DataOps just helps with the confusion of how to apply these principles in data analytics projects.
If after reading all this your wondering – that’s a lot of work and not sure if this will pay off, teams without these practices end up spending way more effort anyway and the output is still slow and low quality. Might as well take a chance and make a few changes & see how it goes!