Testing AI based systems
This year’s QA&TEST conference 2020 was another great addition. While planning the event there were discussions on if the event is supposed to be in person or online, turns out doing it online was definitely the right choice. I did miss the traditional Bilbao food from last year and an amazing experience when I was there as a speaker, the online event this year was also well done too.
The AI track of the event had a talk by Parveen Kumar and a panel discussion with a quick 10-minute talk by all panelists followed by discussions on testing AI systems. Had a blast with the panelists, we all were from different backgrounds but surprisingly had very similar thoughts and challenges on talking about testing AI products. Thoroughly enjoyed the talks and presentations and gave me some new insights too which I want to share in this article.
Testing AI starts with data
Folks when thinking about testing AI systems start debating how to get into that black box neural network to figure out what’s going on and how to test it? The challenge off course, these are evolving programs which no one directly controls. In case of machine learning algorithms, the biggest factor is the data used to train the model – and IMHO that’s where testing should start from.
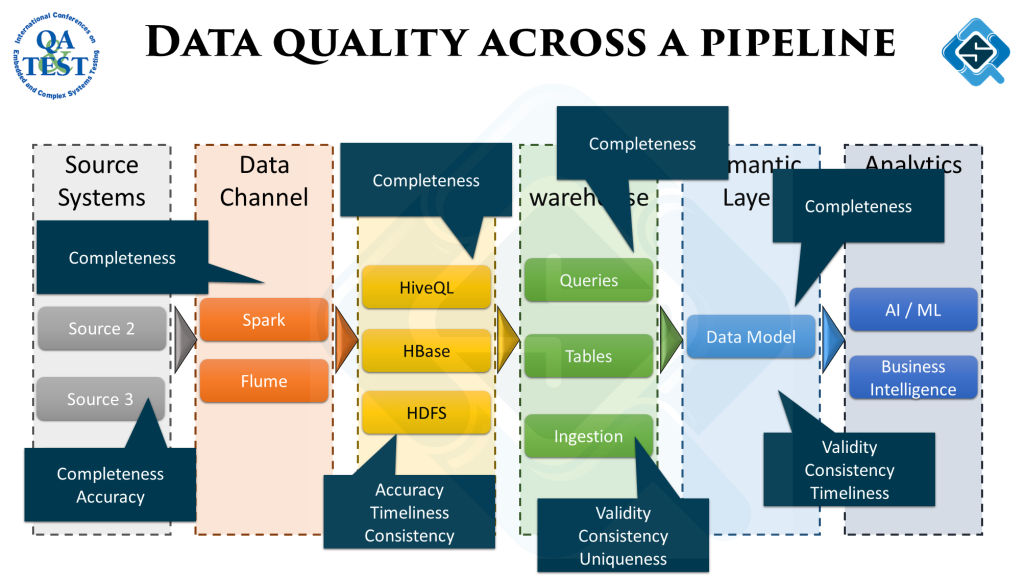
Before loads of data can be fed into the models, all that data needs to be gathered, cleansed and modelled. In my segment I talked about some fundamental concepts like data pipelines, data quality across these pipelines and some quality checks to look out for across different stages.
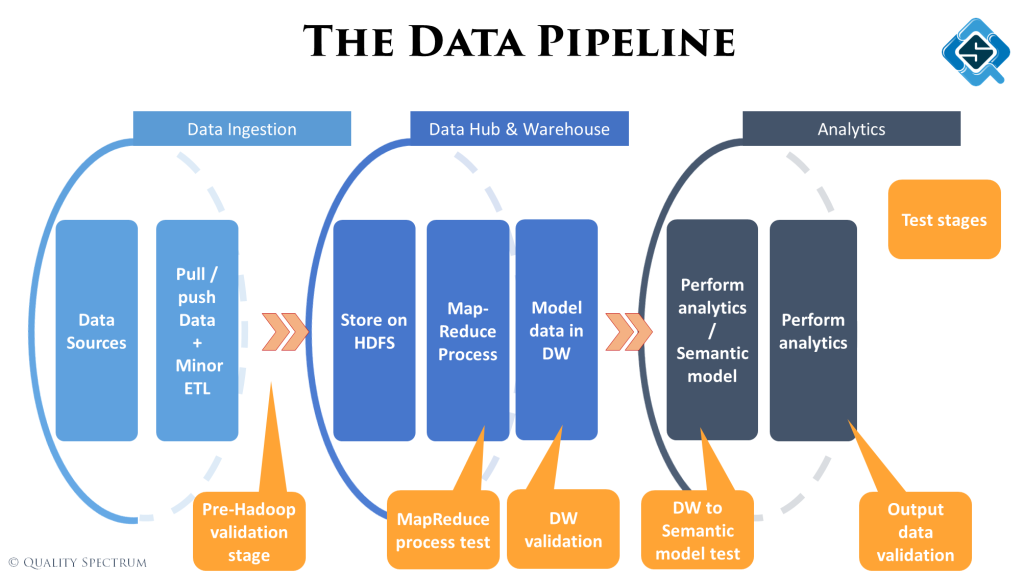
What’s a data pipeline?
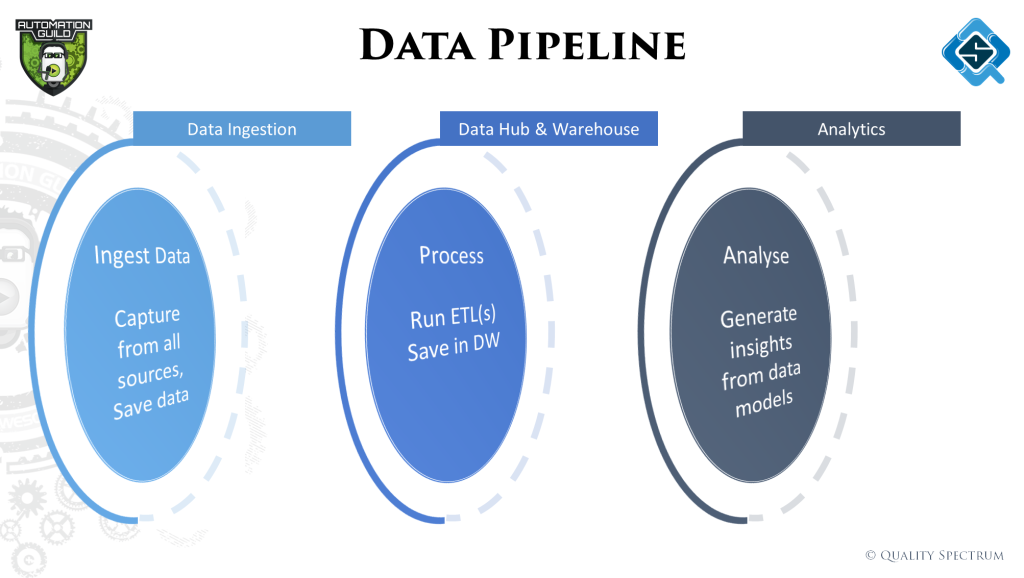
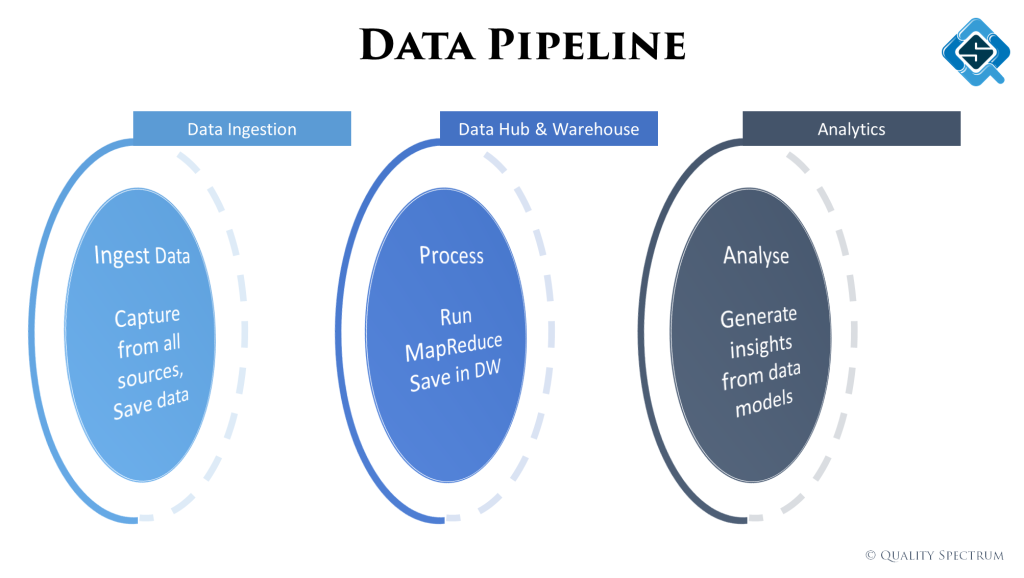
All this usually starts with ‘Big’ data, which means the variety of data, speed of processing and size of data plays a big factor. From gathering this data till feeding it to an AI model, data passes through lots of stages. On a high level we classify them as:
- Data ingestion – Getting data from different sources
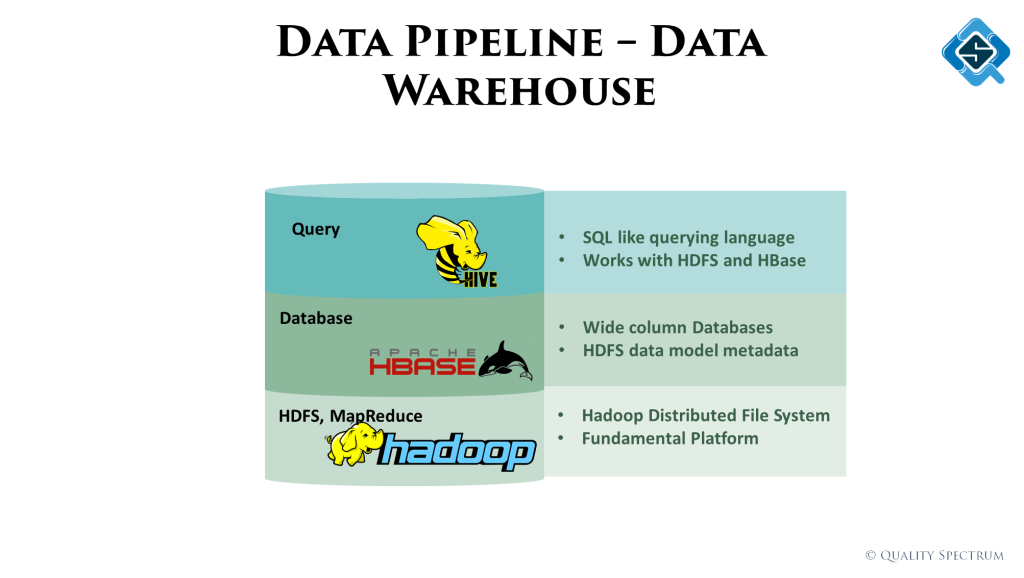
- Data lake & data warehouse – Creating data / domain models and normalized tables
- Analytics – Creating semantic models and running analytics / or feed data into machine learning algorithms
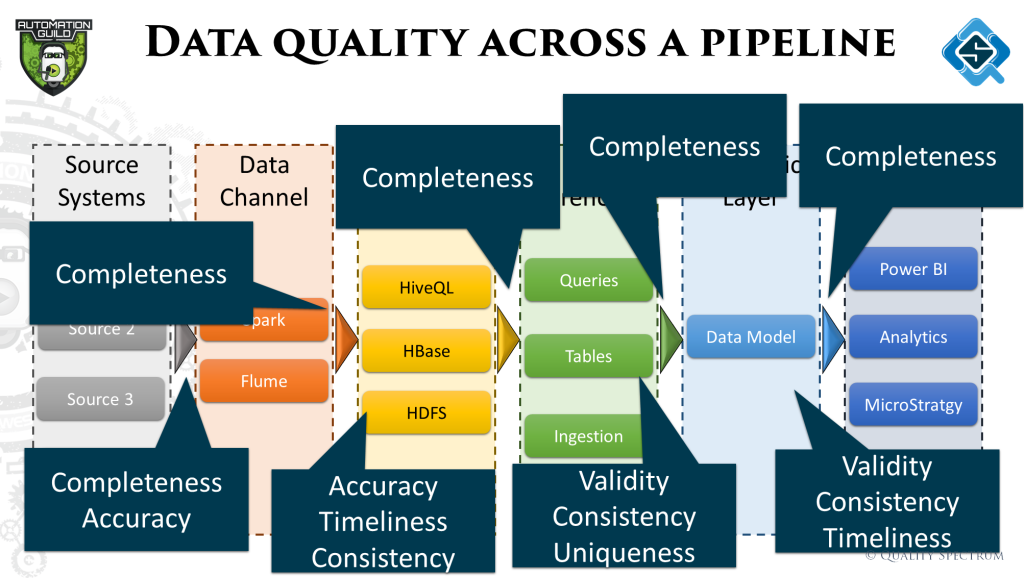
As data is processed through this pipeline, the quality of data has to be measured to ensure as an end output we are able to provide clean data. One of the techniques to do this is data quality dimensions. There are 6 different attributes / characteristics (dimensions) which any data set should conform to. Measuring your data for these dimensions helps to analyze if the data is accurate and fir for purpose.
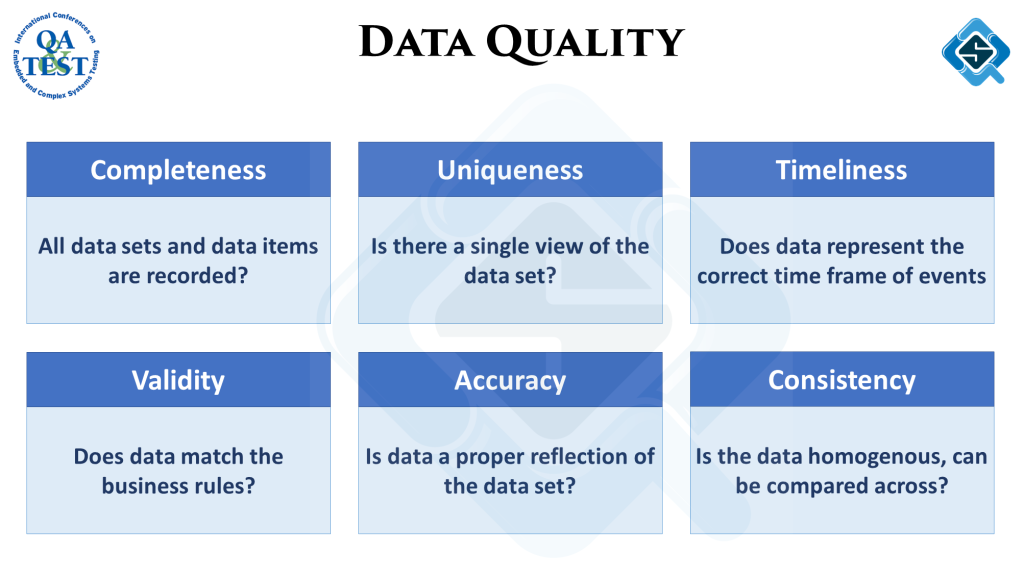
Stages across the data pipeline are curating data with different objectives, therefore the quality dimensions to look out for are also different. While this is a very detailed subject and I usually do a complete talk just on this, the illustrates below summarizes some examples:
Interesting insights
The talks and questions during the panel discussion unearthed some interesting points which I feel might be very helpful for teams exploring to test AI systems.
Regulatory requirements
For safety critical devices regulatory bodies provide practices, processes and guidelines governing how safety approvals will be given. With AI products the community is debating what is more practical and pragmatic approach to certify AI systems.
Due to evolving nature of AI products, it is possible the guidelines will be more process based rather than around the product’s functionality itself since those are going to be a moving target. It goes without saying this is a very complicated problem to solve and the stakes are high. Take an example of self-driving cars and it’s impact.
Continuous learning algorithms
In certain ML models, like deep learning, are mostly ever evolving. After the product is released, it still keeps learning and changing it’s algorithm. This poses a different set of challenges and the traditional test and release cycles are not enough. Observability and production tests become a must in such situations, which means testing becomes an ongoing activity happening in production.
Biases in AI products
AI models build their intelligence through machine learning by consuming large amounts of training data. The kind of data we provide is going to govern the kind of assumptions the model makes. In recent years a few incidences have surfaced where the AI model was biased to a certain group of people or other variables.
The challenge, many times we don’t even know if a bias exists. For instance, a leading tech company had an AI program to short list resumes. Later it was discovered the program assumed highly skilled people are usually male candidates. This was perhaps due to the training data it had, since most candidates who got job offers were men, it made that assumption. Even after knowing the problems it was very hard to fix it, and eventually they had to stop using the said AI program!
The most evident solution is first to figure out any biases that may exist before the training data is provided. The challenge is off course knowing about those biases. What can also help is giving a very wide range of data. Also train & test on every different data sets. This can highlight any incorrect assumptions and biases that might have been built / inferred from the training data set.
Standardizing building and testing AI systems
While regulators and the wider community is looking for ways to have some baseline practices, however the use cases of AI are very widespread and validating the underline algorithm is challenging, it’s going to be hard to reach some generic product-based validations.
Having said that, there are some techniques which can help look at these solutions from a different paradigm, which can be used as good techniques to identify potential risks in such systems. One such technique is STPA which suggests an alternative top down approach of looking at holistic systems and focusing just on safety instead of focusing on the system’s functionality.
Challenges ahead
The field of AI is exciting and has lots of applications. By now we are already seeing many products started to use AI in some capacity. This is going to ever increase because of AI’s capability to process multi-dimension factors and process large amounts of data which can be hard for humans to do.
Apart from topics discussed above, the key challenge IMHO is going to be lack of skills. Looking after the quality aspect is going to be even more challenging, these systems needs engineers who have technical insights into how the underlying technology works plus have ‘testing Acumen’ to test well. While this has always been a problem, seems with AI systems & Big data projects this will be an even bigger one.